雖然目前深度學習的技術是開發語音辨識系統的主流,而且也已經取得不錯的成果。但如果要了解語音辨識系統的架構、運作原理,就必須要從傳統的語音辨識技術開始說起。
傳統的語音辨識系統主要包含3部分
其中聲學模型和語言模型是分開訓練,一般常使用高斯混合模型(GMM-HMM) 作為系統架構,如下圖: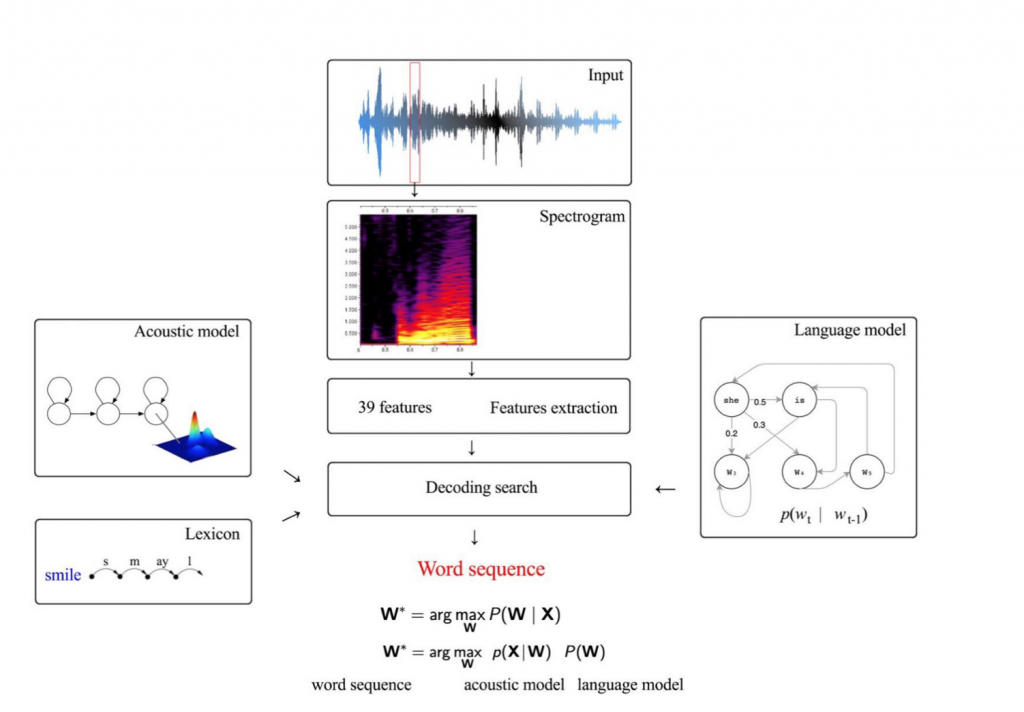
Seq2seq 架構圖,圖片來源: https://jeddy92.github.io/JEddy92.github.io/ts_seq2seq_intro/
語音辨識的原理其實可以簡單地用一個數學式表達:
W 是辨識得到的文字序列,X 是輸入的音訊(包含多個音框, frame),因此目標就是在已知的輸入音訊下,找出機率最
高的輸出文字序列。透過貝氏定理(Bayes' theorem) 可將上述數學式轉換成:
其中,P(X|W) 表示給定一文字序列 W 下出現音訊 X 的機率,即為聲學模型(AM);P(W) 表示文字序列W出現的機率,即為語言模型(LM)。
但是隨著深度學習的發展,愈來愈多的研究開始使用類神經網路(Neural Network, NN) 去取代GMM,形成 DNN-HMM 的混合(hybrid)架構,達到與GMM-HMM相同甚至更好的表現。到了現在,研究人員連 HMM 也捨棄不用,讓整個語音辨識系統全由單一神經網路構成,像這樣從輸入端到輸出端只透過一個神經網路模型完成稱做端到端(end-to-end)語音辨識。
第二天的內容就到這邊,接下來將會介紹什麼是端到端(end-to-end)語音辨識 !
參考資料: https://engineering.linecorp.com/zh-hant/blog/speech-technology-0207/

